
Outline
- Introduction
- What is event-driven architecture?
- How it works
- Architecture model
- Advantages
- Conclusion
- Helpful links
Introduction
A good practice applied in modern software development is the separation of concerns (similar to the Interface Segregation Principle from SOLID principles). Here, similar components that work together are developed in cohesive groups, and interfaces are provided for data sharing between separate groups, thus reducing the amount of tight coupling between critical components of the software.
One way of quickly identifying potential use cases in functions or modules that makes up an application are areas that depend on other external functions--which do not directly impact the functionality of such a module--to complete an action.
How can we effectively ensure loose coupling in such use cases? A good way of achieving this is adopting an event-driven architecture.
What is event-driven architecture?
Event-driven architecture is a software architecture in which data processing and sharing between different components of an application are done asynchronously via events. It is commonly used in applications built with microservices.
An event is a representation of an action that occurs, which causes a change in the state of the application. This state change could be a result of internal or external processes that influences the application.
How it works
An event-driven architecture is typically composed of 4 main components: Data source(s), Producer(s), Consumer(s), and an Event-processing platform. Let's describe each of these components:
- Data Source: A data source is an external entity that produces data that alters an application state. This data could be in the form of user input from a web/mobile application or an output of a processed data from an external service.
- Producer: A producer is the part of the application(module, service, etc) that receives data from the data source as an input, processes the data, and creates an event that represents a change in the state of the application.
- Consumer: A consumer is the part of the application that responds to events created by the producers and performs an action in response to such an event. The producer and the consumer are independent, and unaware of the existence of each other, but are only aware of the event processing platform.
- Event processing platform: An event processing platform serves as a mediator that coordinates the exchange of events between producers and consumers. It receives the events created by the producers and transmits the events to the consumers. Depending on the model adopted, it could function as a message broker or an event store. An example of an event processing platform is Apache Kafka.
The diagram below gives a summary of these concepts:
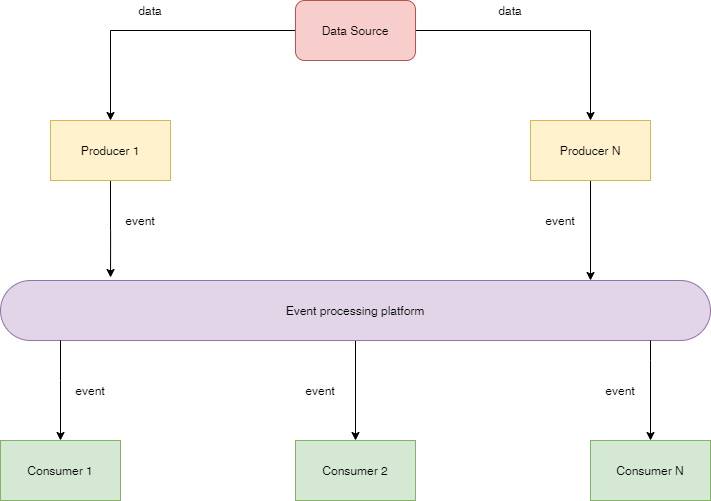
Architecture models
Two major models of the event-driven architecture are the publisher/subscriber model and the event streaming model.
- Publisher/Subscriber Model: Also known as pub/sub model, the publisher/subscriber model is an implementation of the event-driven architecture in which a publisher(producer) sends an event (which may also contain data) to a message channel (aka topic) and one or more subscribers(consumers) subscribe to such channel and listens for events. When a new event is published by the publisher, all interested subscribers on the channel are notified of such event, receive the accompanying data/message (if any), and handles the event appropriately. Each event is triggered as a result of a change in the state of the application. The message broker is responsible for the delivery of events--and their respective data--to the different subscribers. This is described in the diagram below:
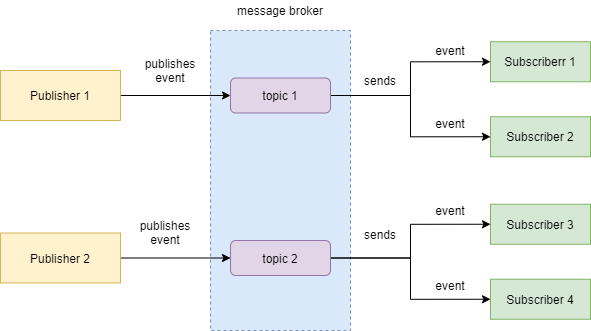
- Event streaming model: In this model, events are represented as continuous streams, and each event is written to a log as they occur. The log represents a history (state) of the application because it contains all events that have occurred in the application. Producers can continuously write(append) to the log, and consumers can read from any point in the event stream, and process such streams. As a result of this, the application state can easily be rebuilt and restored if it gets corrupted or lost. This model can be illustrated as shown below:
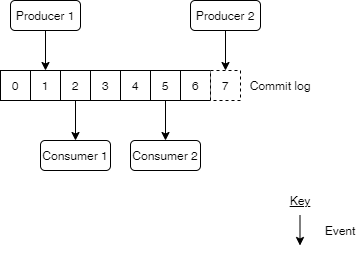
(To learn more about the log, check out this blog post)
Advantages
The event-driven architecture has several advantages, some of which are:
- Loose coupling: The architecture ensures that producers and consumers are unaware of each other, as producers create events in a "fire-and-forget" nature, which ensures that modules/services are decoupled, and eliminates any form of direct dependency.
- Scalability: As a result of its loosely coupled nature, producers and consumers can be scaled independently of each other.
- Improved reliability: It ensures that failure occurrence in producers does not cause a ripple effect in consumers and vice versa, thus improving the reliability of the application as a whole.
Conclusion
Event-driven architecture is one of the ways of enforcing loose coupling in a project, which aids its maintainability. Of course, it doesn't apply to every project, so due considerations should be made before adopting it.


