How to create a flexible backend software architecture.
A practical example using NodeJS (Express), PostgreSQL & MongoDB.

Outline
- Scope of the article.
- Introduction.
- Prerequisites.
- Project setup.
- What is a good software architecture?
- Practical use cases.
- Practical demonstration of the clean architecture.
- Conclusion.
- Helpful links.
Scope of the article
This article teaches about how to implement a flexible backend architecture at the granular level with a practical example demonstrated using NodeJs (Express), MongoDB & Postgres.
Non-scope: This article does not teach about building REST APIs with NodeJs. Prior knowledge of this is expected.
Disclaimer: Software architecture is a broad concept composed of several components and involves a lot of technical decisions to achieve. Owing to this, the concepts taught in this article are by no means an all-encompassing standard that guides building a scalable architecture, but rather seeks to demonstrate its fundamental principles at the most basic level. Feel free to adopt the concepts that best suit your project or organization.
Introduction
A common experience among private individuals building software and tech companies of varying sizes (startups, mid and large) is the need to build products fast.
In most cases, market research is carried out to validate the viability of a product idea, after which a Minimum Viable Product (MVP) is built. An MVP is the initial executed version of the product idea with minimum features required to establish a market presence, attract early customers and gain as much user feedback as possible, after which several iterations are done to improve the product based on the user feedback.
Usually, some of the long-term goals for any software product are scalability and maintainability. A product that scales would be able to accommodate an increasing number of users. A critical factor that affects the scalability of such software products is the architecture. Good architecture is easy to maintain, thereby ensuring that engineers can iterate quickly and build efficiently. Conversely, a poorly implemented architecture would inhibit software engineers from iterating quickly and accumulate a great deal of technical debt which would eventually incur losses (technical & financial resources) on the business.
Owing to this, how can software engineers structure their architecture in a way that is scalable and flexible to changes?
In this article, we would learn about what a good software architecture looks like and how to implement it by comparing two use cases.
Prerequisites
The following prerequisites are required for this article:
Basic knowledge
- NodeJs (Express), MongoDB & PostgreSQL.
- KnexJs and Mongoose .
- Basic knowledge of REST APIs & Postman.
Technical stack
- NodeJs (v8 or higher) & npm
- MongoDB
- PostgreSQL
- Postman
Project setup
In order to follow along with the example project, clone this repo and follow the instructions detailed in its ReadMe file for the local development environment setup.
The project is a simple CRUD application with the following functionalities
- creating a user
- retrieving a single user
- retrieving all users
- updating a user
- deleting a user.
What is a good software architecture?
The architecture of a system is the shape or structure of the system created by the developers of such system. A good software architecture is one in which components of the system can be changed without compromising the core functionality (business logic). in order words, options such as the database management system (SQL, NoSQL, Graph, etc) API strategy (REST, GraphQL, etc), delivery platform (web, desktop, etc) should be flexible to changes without necessarily affecting the overall performance of the system.
Practical use cases
In order to gain a practical understanding of what a flexible architecture looks like, let's analyze the project example.
The major use cases we would look at are:
- regular architecture
- clean architecture
Regular Architecture
The folder labeled regular is an architecture that is commonly used in small and medium-scale projects. Below is its structure:
clean-architecture-example
└─ regular
├─ controllers
│ └─ users.js
├─ database
│ ├─ index.js
│ └─ users.js
└─ routes
└─ users.js
The regular folder follows a typical Express.js project structure. It is composed of the following sub-folders:
controllers: This folder comprises files that contain the core business logic responsible for the functionality of different modules of the application. In this case, it consists of a single file named
users.js, which we would examine later.database: The database folder usually houses the
modelsandmigrationfiles for the database. In this project, it consists of:- the index.js file which is an improvised in-memory database. Below is its content:
let database = {};
module.exports = {
getDB: () => {
if (!database) {
database = {};
}
return database;
}
};
- the
users.jsfile, which contains the methods for accessible basic CRUD functionalities of the database, as shown below
const database = require('./index');
class User {
constructor() {
this.db = database.getDB();
this.index = 0;
}
create(inputFields) {
this.index += 1;
this.db[this.index] = inputFields;
}
findAll() {
return Object.values(this.db);
}
findByEmail(email) {
let found = false;
let possibleUser = null;
Object.values(this.db).forEach((user) => {
if (user.email === email) {
found = true;
possibleUser = user;
return;
}
});
return possibleUser;
}
findById(id) {
return this.db[id];
}
update(id, inputFields) {
this.db[id] = { ...this.db[id], ...inputFields };
}
delete(id) {
delete this.db[id];
}
}
module.exports = User;
This architecture is easy to get started with but is fundamentally not scalable as a result of its tightly coupled structure.
Analysis
To demonstrate, let's examine the file named users.js contained in the controllers folder:
const userModel = require('../database/users');
const UserModel = new userModel();
class Users {
/**
* @async
* @param {object} req express request object
* @param {object} res express response object
*/
static create(req, res) {
try {
const { lastName, firstName, email, password } = req.body;
if (!lastName || !firstName || !email || !password) {
return res.status(400).json({ message: 'incomplete input fields' });
}
const possibleUser = UserModel.findByEmail(email);
if (possibleUser) {
return res.status(409).json({ message: 'user already exists' });
}
UserModel.create({ lastName, firstName, email, password });
return res.status(201).json({ message: 'user created successfully' });
} catch (error) {
console.error(error);
}
}
/**
* @async
* @param {object} req express request object
* @param {object} res express response object
*/
static findAllOrOne(req, res) {
try {
const { id } = req.params;
if (!id) {
const allUsers = UserModel.findAll();
return res.status(200).json({ users: allUsers });
}
const possibleUser = UserModel.findById(id);
if (!possibleUser) {
return res.status(404).json({ message: 'user does not exist' });
}
return res.status(200).json({ user: possibleUser });
} catch (error) {
console.error(error);
}
}
/**
* @async
* @param {object} req express request object
* @param {object} res express response object
*/
static update(req, res) {
try {
const { id } = req.params;
const possibleUser = UserModel.findById(id);
if (!possibleUser) {
return res.status(404).json({ message: 'user does not exist' });
}
UserModel.update(id, req.body);
return res.status(200).json({ message: 'user updated successfully' });
} catch (error) {
console.error(error);
}
}
/**
* @async
* @param {object} req express request object
* @param {object} res express response object
*/
static delete(req, res) {
try {
const { id } = req.params;
if (!id) {
return res.status(400).json({ message: 'id param is required' });
}
const possibleUser = UserModel.findById(id);
if (!possibleUser) {
return res.status(404).json({ message: 'user not found' });
}
UserModel.delete(id);
return res.status(200).json({ message: 'user deleted successfully' });
} catch (error) {
console.error(error);
}
}
}
module.exports = Users;
From the above file, the following observations could be made as examples of tight coupling:
database query functions are called directly in this file, as reflected by the import on line 1. A disadvantage of this is that changes made to the
userModelwould directly affect the business logic of the application.the business logic contained in the
controllers/users.jsfile has been directly bound to a single type of database (in this case, the in-memory database). A change in the type of database used (e.g MongoDB) would mean that several parts of this file containing database query methods would be changed as well. Once again, the business logic has been affected by a non-business factor.
Ideally, the business logic should only be modified if there is a change in the business requirements. Therefore, we need to structure our application in such a way that the critical component of the application (business logic) should not be affected by the less-critical component of the application (database, API strategy, delivery platform etc).
An alternative architecture that effectively handles the above concerns is discussed below.
Clean Architecture
A cleaner and more flexible architecture is one that is loosely coupled and modular in nature. This means that there is a clear separation of concerns and modularity is implemented in a manner that ensures code reuse.
To demonstrate its flexibility, two different database management systems were used namely: PostgreSQL & MongoDB. I applied lessons learned from Clean Architecture ( Robert C. Martin) and Domain-Driven Design (DDD).
The folder called clean_architecture is structured as shown below:
clean-architecture-example
├─ clean_architecture
│ ├─ config
│ │ ├─ dbConnection.js
│ │ └─ useCases.js
│ ├─ core
│ │ ├─ definitions
│ │ │ ├─ ErrorResponse.js
│ │ │ └─ SuccessResponse.js
│ │ ├─ entities
│ │ │ └─ User.js
│ │ └─ use_cases
│ │ └─ user
│ │ ├─ CreateUser.js
│ │ ├─ DeleteUser.js
│ │ ├─ GetSingleUser.js
│ │ └─ UpdateUser.js
│ ├─ data
│ │ ├─ database
│ │ │ ├─ nosql
│ │ │ │ ├─ index.js
│ │ │ │ └─ models
│ │ │ │ └─ user.js
│ │ │ └─ sql
│ │ │ ├─ config
│ │ │ │ ├─ knex.js
│ │ │ │ ├─ knexfile.js
│ │ │ │ └─ tableNames.js
│ │ │ └─ migrations
│ │ │ └─ 20210822143115_users.js
│ │ └─ implementations
│ │ ├─ index.js
│ │ ├─ nosql
│ │ │ └─ user.js
│ │ └─ sql
│ │ └─ user.js
│ └─ entry_point
│ └─ web
│ ├─ controllers
│ │ └─ user.js
│ ├─ helpers
│ │ └─ generateResponse.js
│ └─ routes
│ └─ users.js
This folder is made of 4 key sub-folders namely:
config: This folder contains all the configuration files needed by the project. It is composed of 2 major files namely:
dbConnection.js, which handles the MongoDB connectionuseCases.js, which is an orchestrator file for the use cases (more on that later)
core: As the name implies, this folder is the fundamental core of the application. It comprises 3 subfolders namely:
- definitions: This contains reusable API response functions for success and error responses namely:
SuccessResponse.jsandErrorResponse.js. - entities: It contains core business objects. In this project, the
entitiesfolder contains a single business object specified inUser.js. - use_cases: This folder contains the core business logic for the various business domains and their related functionalities. In this project, a single business domain, user, is specified by the
userfolder, with its related domain functionalities namely:CreateUser.js,DeleteUser.js,GetSingleUser.jsandUpdateUser.js, as the names imply.
- definitions: This contains reusable API response functions for success and error responses namely:
data: This contains the database-related functionalities. It contains the following sub-folders:
- database: This folder contains the required database config folders for the
sql(PostgreSQL) andnosql(MongoDB) databases. - implementations: This folder contains
sqlandnosqlsubfolders, which contain required files for the implementation of the sql and nosql databases respectively, following the repository design pattern. In addition, it contains a singleindex.jsfile, which serves as an orchestrator file that dynamically selects the database implementation to be used in the application.
- database: This folder contains the required database config folders for the
entry_point: This is the folder that contains platform-specific configuration (web, desktop), which is essentially the mode of delivery of the software. For this project, the platform can be deployed on the web, which is why there is a single
webfolder containing the necessary framework-related configuration required for the deployment of the application (i.e. controllers, routes, middleware, etc).
Analysis
As an example, let's analyse the CreateUser.js file contained in clean_architecture/core/use_cases/user folder:
const SuccessResponse = require('../../definitions/SuccessResponse');
const ErrorResponse = require('../../definitions/ErrorResponse');
class CreateUser {
constructor(userRepo) {
this.userRepo = userRepo;
}
async execute({ lastName, firstName, email, password }) {
try {
// simple validation
if (!lastName) return ErrorResponse.badRequest('lastName is required');
if (!firstName) return ErrorResponse.badRequest('firstName is required');
if (!email) return ErrorResponse.badRequest('email is required');
if (!password) return ErrorResponse.badRequest('password is required');
const possibleUser = await this.userRepo.findByEmail(email);
if (possibleUser) {
return ErrorResponse.conflict('user already exists');
}
// create user
const createdUser = await this.userRepo.createUser({
lastName,
firstName,
email,
password
});
return SuccessResponse.created('user created successfully', createdUser);
} catch (error) {
console.log(error);
throw error;
}
}
}
module.exports = CreateUser;
The following observations could be made:
- the file depends on only the
SuccessResponse.jsandErrorResponse.jsfiles, which do not change - The database model dependency is injected via the constructor. Note that the
CreateUser.jsfile is unaware of the particular type of database system (sql/nosql) responsible for the model file. - Necessary user input is passed as an argument to the
executefunction. - The model configuration is handled by the
index.jsfile in theclean_architecture/data/implementationsfolder:
const dotenv = require('dotenv');
const appPath = require('app-root-path');
const UserRepo_sql = require('../implementations/sql/user');
const UserRepo_nosql = require('../implementations/nosql/user');
dotenv.config({ path: `${appPath}/.env` });
const sqlRepos = {
UserRepo: UserRepo_sql
};
const nosqlRepos = {
UserRepo: UserRepo_nosql
};
const dbType = process.env.DB_TYPE || 'sql';
let finalRepositories = null;
switch (dbType) {
case 'sql':
finalRepositories = sqlRepos;
break;
case 'nosql':
finalRepositories = nosqlRepos;
break;
default:
finalRepositories = sqlRepos;
break;
}
module.exports = finalRepositories;
This ensures that the business logic files contained in core/use_cases remain independent of the type of database, delivery platform, or API strategy used.
Practical demonstration of the clean architecture
To demonstrate, we would test the concept learned in the clean architecture by using MongoDB & PostgreSQL, using the env variable: DB_TYPE to switch between the different databases.
We would be testing the CreateUser functionality in Postman using the route: http://localhost:5000/ca/users
Tip: Ensure that your MongoDB and PostgreSQL server is running on your local machine.
Example 1: MongoDB
By setting the DB_TYPE=nosql, we have instructed the system to use MongoDB. Using Postman, the result is as follows:
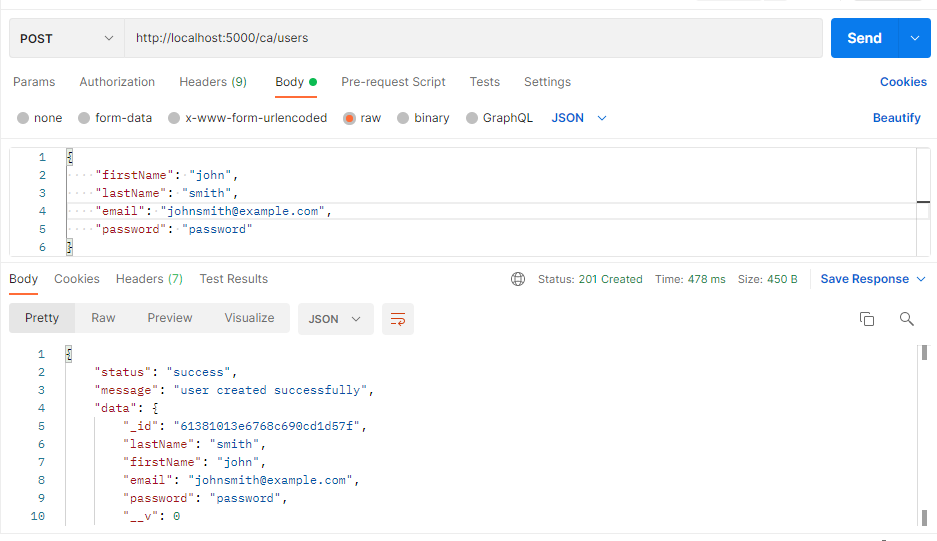
Example 2: PostgreSQL
Using the same route as Example 1 above, set DB_TYPE=sql and restart the development server. The result is as follows:
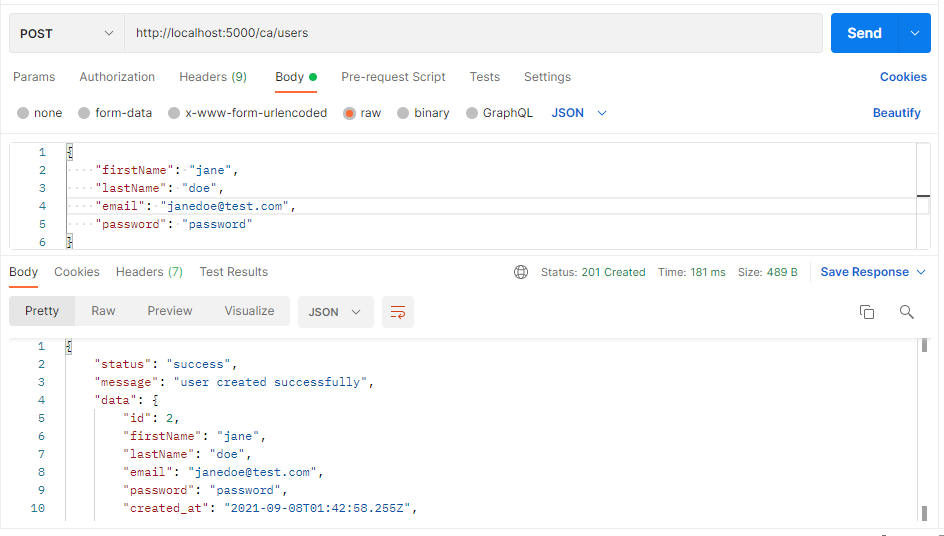
This shows that we can use 2 different database management systems by changing the value of a single env variable- DB_TYPE without interfering with the core business logic of the application!
Conclusion
The development process of a software product varies across organizations and is largely affected by its needs--as determined by the individual/organization responsible--and the deadline attached to the product launch. While the ability to iterate fast is important, care should also be taken to ensure that the architecture of the software is structured in a manner that is scalable, flexible, and maintainable.


